前言:服务器选型中功耗压测非常重要,普通服务器的功耗主要压测CPU、内存、磁盘,使服务器运转到高负载的情况观察服务器的功耗情况,获得的数据在未来IDC规划每个模块、每个机柜能上几台服务器中有重要参考价值。常见的压测工具有stress-ng、memtester、fio等。当前在做GPU服务器的选型,因之前没有GPU功耗压测的经验,所以走了很多弯路子,趁此机会做整理供各位参考。
1、安装A100驱动
标红的选项要注意后面的cuda安装是需要搭配这个使用
下载链接:https://www.nvidia.cn/Download/index.aspx?lang=cn
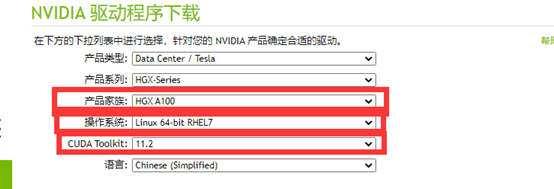
下载完成上传到服务器
安装驱动命令:
yum install nvidia-driver
2、安装cuda 11.2
下载链接: https://www.nvidia.cn/Download/index.aspx?lang=cn
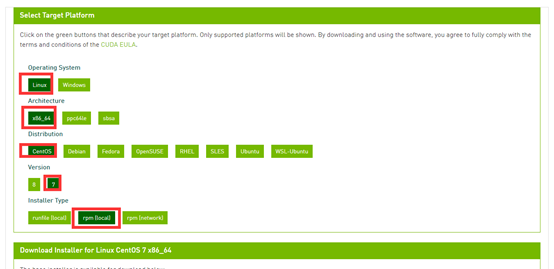
安装命令:
rpm -i cuda-repo-rhel7-11-2-local-11.2.0_460.27.04-1.x86_64.rpm
yum clean all
yum -y install cuda
安装完成重启服务器:reboot
注意此处不要安装cuda包自带的驱动。
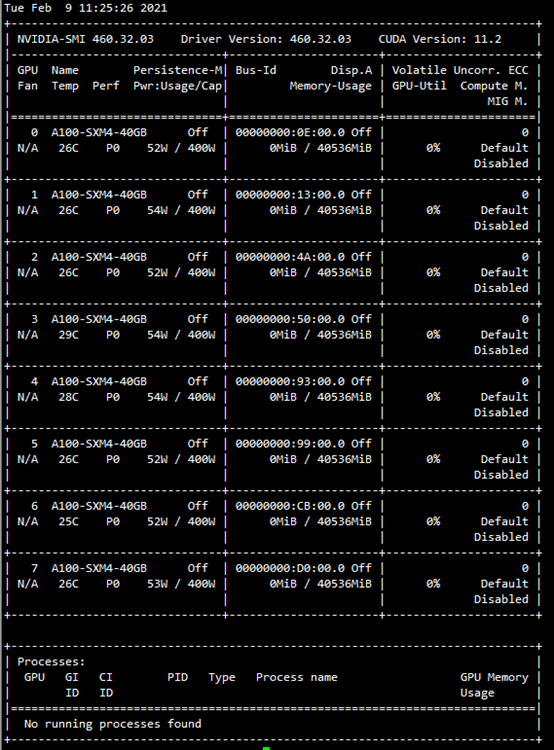
3、检查NVIDIA GPU卡
执行命令:nvidia-smi 可以看到所有的GPU卡信息,如果不能看到请检查前两步是否有错,或联系厂商检查GPU硬件或主板硬件。
4、安装DCGM
注:从官网下载DCDM 需要注册NVIDIA账号
DCGM页面:
https://developer.nvidia.com/dcgm
DCGM下载链接
若是其他OS可以自己这找下
https://developer.download.nvidia.cn/compute/cuda/repos/
安装DCGM:
rpm -ivh datacenter-gpu-manager-2.1.4-1-x86_64.rpm
安装完成启动此服务:
systemctl start nvidia-dcgm
注:如不启动此服务后面无法创建GPU Group
5、安装nvidia-fabricmanager
注:安装此工具必须和驱动同一版本号
下载此安装包并安装
rpm -ivh nvidia-fabricmanager-460-460.32.03-1.x86_64.rpm
下载此安装包的开发板并安装
rpm -ivh nvidia-fabricmanager-devel-460-460.32.03-1.x86_64.rpm
安装完成启动服务
systemctl start nvidia-fabricmanager
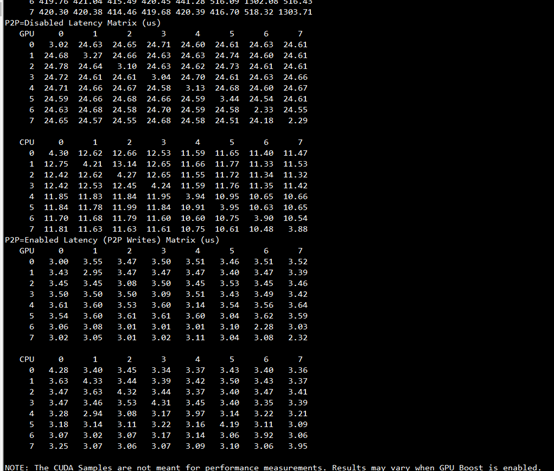
6、简单测试
cd /usr/local/cuda-11.2/samples/1_Utilities/p2pBandwidthLatencyTest
make
./p2pBandwidthLatencyTest
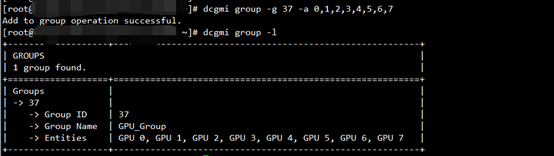
7、创建GPU Group
dcgmi group -c GPU_Group
创建了一个ID 为37的group

查看group 列表
dcgmi group -l

将GPU加入到group组
dcgmi group -g 37 -a 0,1,2,3,4,5,6,7
-g 37为加入id为37的group组,-a 后面为GPU的ID可以通过nvidia-smi查找
通过dcgmi group -l 可以看到Entities里有了刚添加的GPU
8、启用功耗压测
dcgmi diag -r “targeted power” -p “targeted power.target_power=400;targeted power.test_duration=30” 注:30为压测秒数
可以使用watch -n 1 ‘nvidia-smi’进行查看GPU功耗使用情况
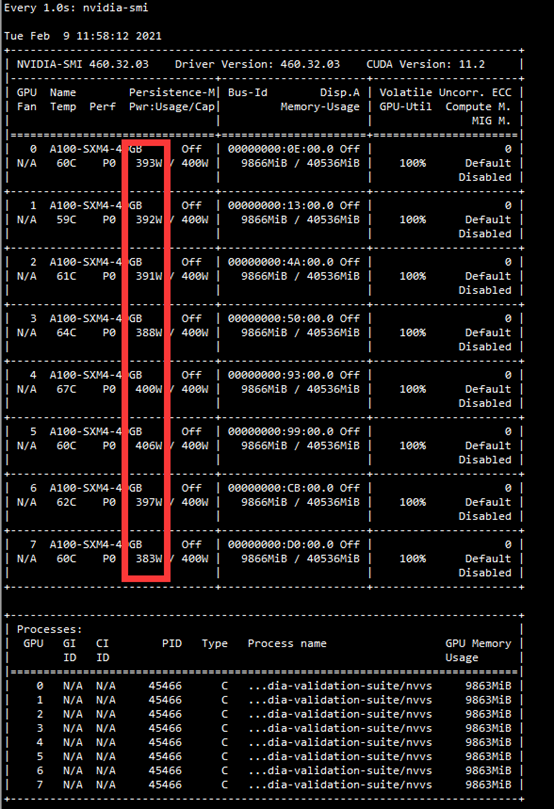
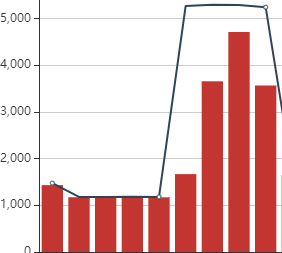
通过BMC WEB界面可以看机器的功耗直线上升,也可以通过ipmitool获取到机器的功耗信息,BMC WEB功耗截图示例: